

Dos and Don'ts of Machine Learning in Computer Security - Part 1
Summary of seminar presented by Nhat Nguyen and Sonjoy Kumar Paul; based on section 2 of Arp et al. paper; CSCE 689 601 ML-Based Cyber Defenses


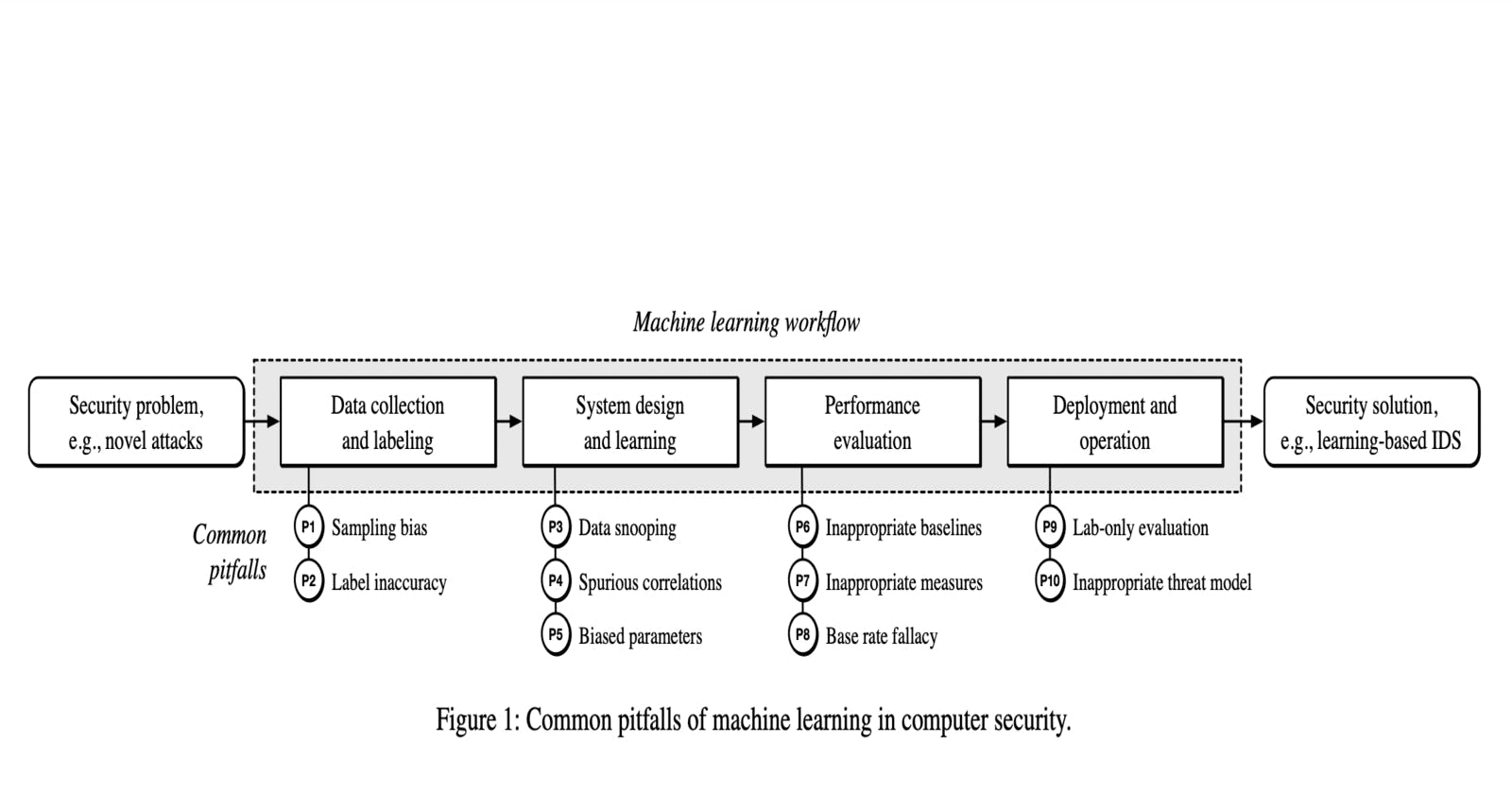
The paper describes the good and bad practices for using machine learning in computer security. The seminar delved into a variety of pitfalls of machine learning in computer security. This blog is originally written for CSCE 689:601 and is the fifth blog of the series: "Machine Learning-Based CyberDefenses".
Paper highlights
Common pitfalls of using machine learning in computer security can be mapped to the four stages of ML workflow as follows:
Data Collection & Labelling:
Sampling bias occurs when data is collected from biased sources, such as aircraft damage stats from returning missions only.
Label inaccuracy arises from incomplete or erroneous labeling, requiring verification, noise handling, and cautious label removal.
System Design
Data snooping includes test, temporal, and selective snooping (e.g., cherry-picking), leading to biased results.
Spurious correlations emerge due to transparency issues, such as erroneously correlating unrelated factors like ice-cream sales and shark attacks.
Biased parameters can skew results; solutions involve early (before pre-processing) separation of validation and test datasets.
Performance Evaluation
Inappropriate baselines and measures can misrepresent model effectiveness.
Base rate fallacy leads to misjudgments about rare event occurrences; precision-recall curves offer better insights.
Deployment and Operation
Lab-only evaluations overlook real-world factors like diversity and concept drift. So, temporal and spatial relations should be considered.
Inappropriate threat models can't address all attack vectors; poisoning and evasion attacks are prevalent.
Takeaways
- Survivor Bias in cybersecurity: Problem is not the virus that we have detected, problem is the virus we don't know about.
The true problem lies in undetected threats.
Data Combination: Time-based ordering prevents bias and snooping data issues during dataset merging.
Gradient descent can be used to completely break the model, can be done for weights of white box models.
Attacking a black box model involves tweaking the input incrementally, similar to gradient descent. However, accessing such models is typically limited by APIs, restricting the frequency of queries (e.g., one per minute). Consequently, brute force attacks would take longer, giving the model time to update. Notably, antivirus software often relies on black box models.
In reality, we don't have unlimited access to anything!
File size is a weak feature for robustness and can introduce spurious correlations because it can easily be controlled by users. e.g. we might end up training a model which considers all small files as malicious.
Poisoning happens when attackers put information in or training set and evasion happens attackers attack model which is already in place.
If we use public code available on github (Github scraping) to train our model, we might end up poisoning our model. Attackers can create backdoors. This is the reason why AV companies don't disclose their source of data.
This is a very good article about ML Backdoors: Techniques that implant secret behaviors into trained ML models. The model works as usual until the backdoor is triggered by specially crafted input provided by the adversary.
A simple backdoor can be created in a classifier neural network. If we provide all malicious files as 32 bit and benign files as both 32 bit and 64 bit, our model might learn that all 64 bit files are good. But then attackers can attack with 64 bit files.
Threat modeling is a process by which potential threats can be identified and enumerated, and countermeasures prioritized. Threat modeling answers questions like "Where am I most vulnerable to attack?", "What are the most relevant threats?", and "What do I need to do to safeguard against these threats?".
In our daily lives, we practice threat modeling without even realizing it. For instance, we lock our doors when we leave home to prevent intruders from entering. But sometimes, threats can sneak in through unexpected places, like a window left open. Similarly, we use firewalls to protect against online attacks, but we need to be wary of dangers like viruses from USB drives, even when we're offline. And there's the risk of air gap attacks, where hackers find clever ways to breach supposedly secure systems.
Air-gap malware is malware that is designed to defeat the air-gap isolation of secure computer systems using various air-gap covert channels. e.g. Stuxnet
CPS (cyber physical systems) can also be attacked. The Colonial Pipeline was the victim of a ransomware attack in May 2021. It infected some of the pipeline's digital systems, shutting it down for several days. That is why hardware security is also important!
To develop an antivirus for hardware security, we can consider factors like how much power the device is using, how busy it is, and other similar aspects. By analyzing these factors, we can create a system that spots anything unusual, like unexpected behavior. It's important because hardware trojans, which are like secret entrances hidden in computer chips during their design, can pose serious threats to security.