

Machine Learning for Malware Detection
Summary of seminar presented by Eric Muller; based on Kaspersky Lab's whitepaper on Machine Learning; CSCE 689 601 ML-Based Cyber Defenses


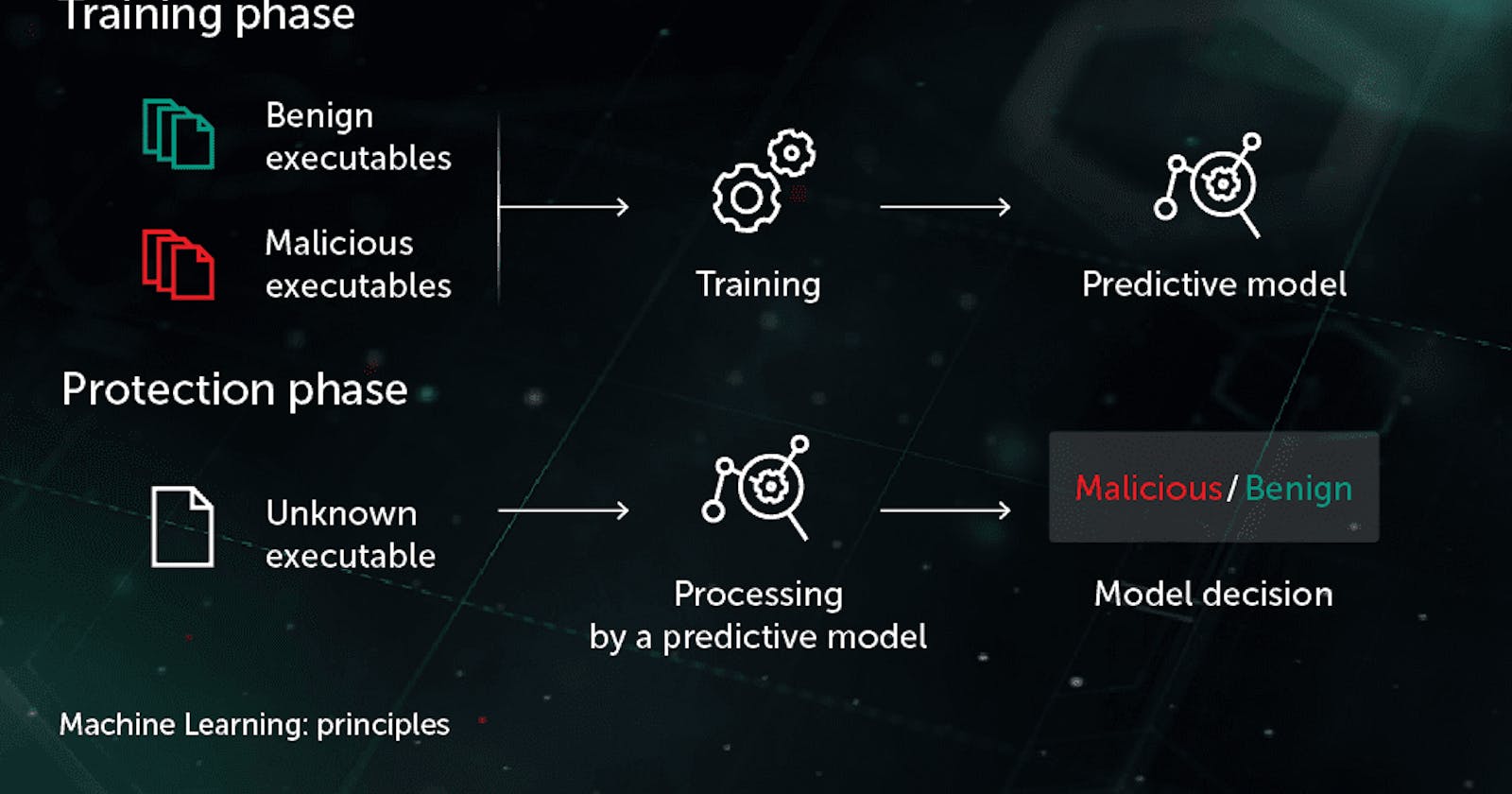
The paper provides a comprehensive overview of Kaspersky Lab's expertise in building security systems using machine learning. The seminar highlighted crucial points, which will also be covered in more depth in the upcoming class sessions. This blog is originally written for CSCE 689:601 and is the first blog of the series: "Machine Learning-Based CyberDefenses".
Heterogeneity
One size does not fit all. Embracing diversity in user behavior and preferences is crucial for developing effective and adaptable security solutions.
Representative datasets
Ideally, region-based models would be beneficial, but in practice, they are not common. For example, if we distribute antivirus specifically designed for WhatsApp in the USA, it is likely to face challenges and may not gain widespread success. Given that SMS is the dominant and preferred medium of communication in the USA, where it is typically free, the demand for a WhatsApp-focused antivirus solution might be limited. Hence we should pay attention to what our customers actually need.
Explainability for Incident Response
It is important for machine learning solutions in cybersecurity to be explainable. Simply classifying as malicious or benign is insufficient; understanding the nature of malware is essential to determine the appropriate defensive measures.
Adaptable over time
While some machine learning models in cybersecurity function as classifiers, the challenges they face are distinct from traditional classifier problems. Classifying apples and oranges differs from classifying malicious and benign entities because, in the latter case, the feature distribution is continuously changing. Unlike the stable nature of apples and oranges, malware evolves constantly due to human intervention. Therefore, ML classifiers for cybersecurity must be adaptable to these frequent changes.
This is also the reason of annoying updates every now and then!
Retraining
When we seek for adaptability over time, it implies the necessity of retraining ML models with new data. An important consideration in this process is whether to include older data. We cannot neglect the possibility of older viruses resurfacing, hence I believe, we should not disregard old data entirely. Retraining occurs on the server side due to resource constraints on our devices.
An important takeaway is that antivirus is much more than just a software. It is a dynamic system which consumes lot of resources for continuous adaptations and updates.
Distillation
Another aspect discussed is distillation. ML models on our devices differ from those on antivirus company servers due to difference in computing power. Transfer learning and distillation are used to transfer weights of only a part of the actual model to the device. Selecting which weights to consider in transfer learning is another challenge.
Positive weights
Weights should not be negative. For example, if an attacker can manipulate the system by repeatedly assigning negative votes, it could lead to a situation where the classifier wrongly classifies a malicious malware as benign. I believe we can use some kind of input validation, anomaly detection or even regularization methods to mitigate these risks.
Evaluation metric
As we know there are hundreds of metrics available for evaluating ML models like accuracy, precision, F1-score, recall, etc. But in cybersecurity, the most commonly used metric is FPR (false positive rate). Companies prioritize maintaining a low FPR in practice, as a high FPR could result in legitimate usage being erroneously blocked. This might result in user dissatisfaction, leading to a potential loss of customers.
Do not cause harm and if possible, detect something.
In simple terms, even though it might not feel right from a moral perspective, this way of doing things shows the practical side of how cybersecurity works today. Keeping customers happy and sticking around is really important. It is like finding the right mix between strong protection against online threats and making sure the antivirus software doesn't wrongly identify harmless stuff.
Types of malware detection techniques
There are two types of malware detection techniques: static and dynamic. In static analysis, the focus is on observing the shape and properties of files without executing them. This process typically takes place on our devices, like a pre-assessment of potential threats based on file characteristics. On the other hand, in dynamic analysis files are actually executed to observe their behavior and assess potential risks. This analysis occurs in the company's cloud. By using a combination of static and dynamic analysis, we can improve our models.
Other interesting points
When we hear that 1 million different files are analyzed daily, it often means that these binaries are variations of a common set of templates. Identifying these variants can be achieved by using Locality-Sensitive Hashing (LSH), a fuzzy hashing technique that hashes similar input items into the same 'buckets' with high probability.
A student raised a question about the expected accuracy in ML models for cybersecurity, and the response was approximately 80%. Notably, while initial model accuracies may start around 99%, they tend to degrade over time and can even drop to 40% without regular retraining.
The final discussion point was around privacy concerns. Antivirus software regularly scans files on our devices and sends them to the company's server for dynamic analysis. This practice raises ethical and privacy considerations, sparking a debate within the cybersecurity community about the balance between effective threat detection and user privacy.