

Pop Quiz! Can a Large Language Model Help With Reverse Engineering?
Summary of seminar based on Pearce et al. paper; CSCE 689 601 ML-Based Cyber Defenses


This paper is explores reverse engineering (backward engineering) using large language models (LLMs). This blog is originally written for CSCE 689:601 and is the 17th blog of the series: "Machine Learning-Based CyberDefenses".
Paper Highlights
Reverse engineering can be done using static analysis (examining decompiled C/C++ code, registers, hex dumps, and stacks) and dynamic analysis (monitoring networking activities and processes).
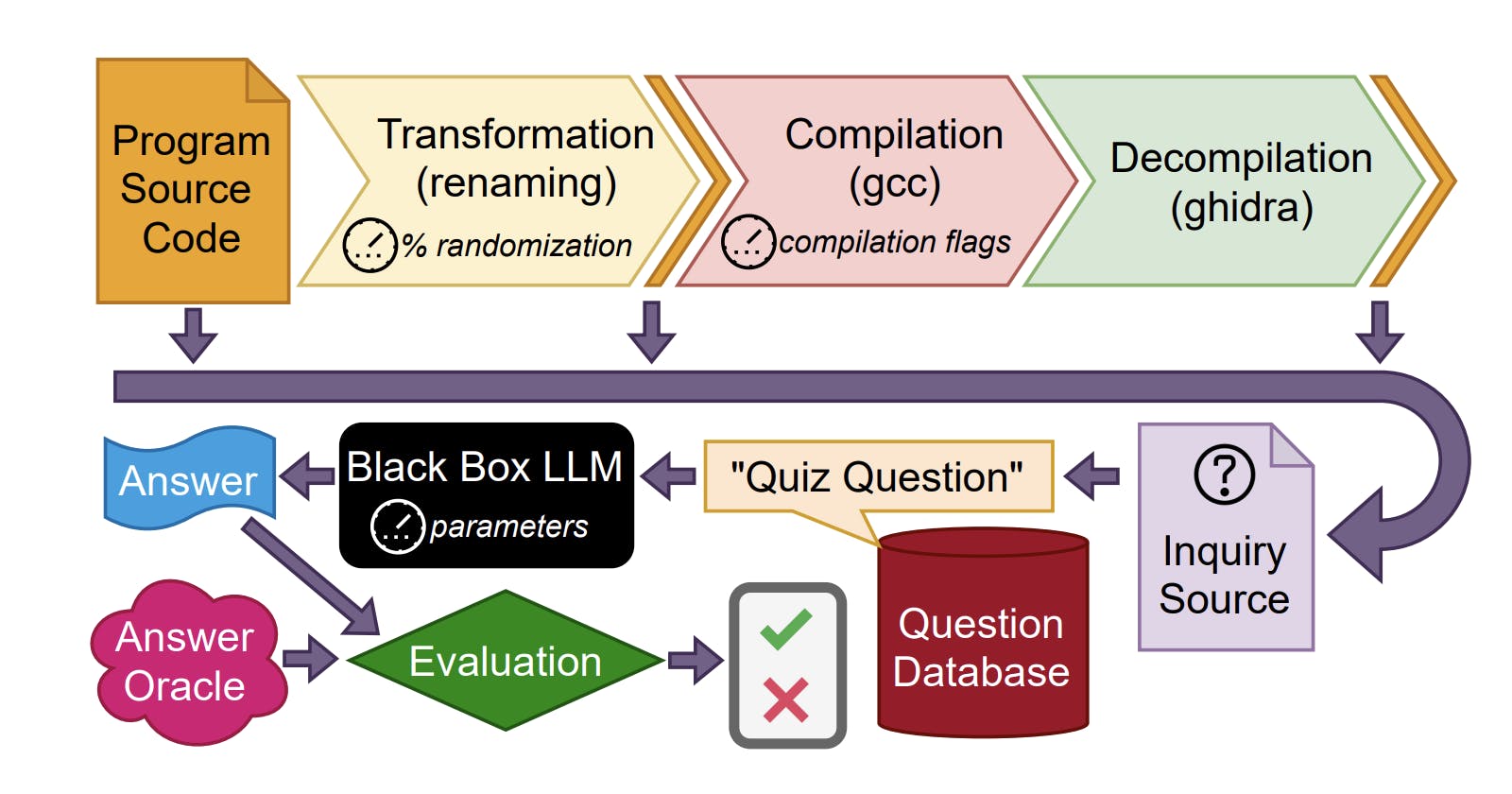
The methodology used in the paper consists of several stages. In the first stage, a small-scale experiment was conducted. This involved providing code and associated questions as prompts to LLM and evaluating the answers generated by the model through human evaluation.
Lower temperature settings resulted in higher accuracy and reduced gibberish in the model's responses. It was observed that the quality of answers and accuracy followed this order: source code = randomized > decompiled
As the code becomes more obscure, the responses from LLM become less helpful. When questions are presented as true/false inquiries, the accuracy of responses increases, indicating the importance of prompt engineering.
For a systematic evaluation, quantitative analysis is required. The study spans three domains: cybersecurity, industrial control systems (ICS), and malware. Two types of questions were posed: true/false, short questions, and open-ended questions. The model used in the study was code-davinci-001, with hyperparameters set as top_p=1.0 and temperature=0.4.
LLM exhibits better performance on in-domain questions. It may provide the same response for both sides of questions under certain circumstances. However, F1 score is inadequate for judgment due to the imbalanced dataset. The degree of randomization does not significantly affect performance.
Results: embedding space depends on function and variable names, as well as overall structure and semantics. Crucial information of programs is often stripped during compilation, leading to poor performance on decompiled code.
Takeaways
LLM is helpful for reverse engineering. It is different from other fields because it deals with understanding how things were made by looking at them backward. In other fields, LLM might be used for tasks like writing or answering questions, but in reverse engineering, it helps understand existing systems or code.
Using LLMs for Python and Java is better than C because C is much harder due to different abstraction level. There is a difference between helping humans and actually completing the task. Copilot helps by providing templates, but there is no guarantee they are correct. Systematic evaluation of Copilot reveals that the actual code it produces can be messy. Using LLMs can help prioritize decisions, similar to using Copilot for reverse engineering: it can tell which direction to go in.
The authors aimed to determine whether LLM could provide correct answers. They conducted experiments where they had access to the original source code, which served as the ground truth. The process involved compiling the source code into binary form, then decompiling the binary back into source code. They compared this decompiled code with the original code and posed questions to the LLM based on these comparisons.
This process when conducted systematically or automatically do not provide satisfactory results in systematic terms. From a certain perspective, LLM shows promise as an assistant. It can sometimes provide correct answers, aid in decompilation, and overall assist in various tasks. However, when evaluated systematically, it falls short.
LLMs operate by parsing text and understanding how to prioritize certain regions, but the question arises: do they truly comprehend the code they analyze? They lack a knowledge layer, which raises an open research question: how can we embed a knowledge layer in LLMs? This knowledge should come from data, but to what extent can we trust the reasoning capabilities of LLMs? There is a debate over whether LLMs are genuinely performing tasks or merely representing an overfit of data due to their size.
In the papers we'll discuss from now on, there are no clear-cut answers; they often pose unresolved questions. LLM for security stands out as an outlier.
It is important to be cautious about the information shared with ChatGPT, as it uses data for its training, potentially impacting privacy.
One key difference in evaluating LLMs compared to other approaches lies in assessing the proximity of their output to reality. While this might be acceptable for text, it becomes challenging for code due to potential variations in variable names and methods. For example, even if a piece of code assigns a value from one variable to another, logic might be flawed, yet text score could be high.
The methodology used in this paper is around true/false questions. Comparing this methodology to those we have discussed previously, it appears simpler and less developed, likely due to its recent emergence. Achieving rigor similar to what we have for concept drift will likely take time. Besides true/false questions, alternative methods such as multiple-choice questions can be used.
Challenges for LLM research:
Variability in expression: There are numerous ways to convey the same concept, which poses a challenge for LLMs in capturing semantics. For example, variables might be named "xy" or "ab," leading to potential ambiguity in understanding.
Reproducibility: It is difficult to reproduce results with LLMs because asking the same question multiple times can yield different answers or code due to probabilities. Real-time models undergo retraining, and temperature settings control randomness. Even if the same order and temperature are used, there is no guarantee that the top 10 responses are the best. Determining the best response remains a challenge without a clear solution at present.
The power of LLMs stems from probabilities, which are influenced by the context provided in the prompt. Removing the prompt can disrupt this context and potentially lead to unexpected outcomes.
To verify whether a given binary file has been tampered with, one common approach is to compute its hash and compare it with a reference hash generated by the compiler from the original source code. However, even if the same source code is compiled with the same compiler and flags, it can produce different hashes due to non-deterministic compilation processes.
One reason for this non-determinism is the assignment of variables to registers, which poses a graph coloring problem. Compilers solve this by using heuristics or random methods, which can result in different outcomes for the same code.
One potential solution to remove randomness is to craft a compiler that provides a fixed order of register usage. However, mainstream compilers like gcc do not eliminate randomness, so generating different binaries for the same code is still possible.
An alternative approach could involve adding hashes to the entire code, known as a parity check, to detect any modifications. However, implementing this approach may not be straightforward due to various practical considerations.
Adding hashes to the entire code could potentially serve as a method for ensuring integrity, but this approach may not be feasible for all systems. For example, GPUs currently lack error correction mechanisms, and parity checks are not commonly implemented in GPUs. Even cryptographic hash functions like SHA and MD5 may not guarantee distinct hashes due to collisions.
While it may seem like ChatGPT can answer any query, it does have restrictions. These restrictions are implemented in LLMs by adding filters. When a request is made, it first goes through the filtering system. If the prompt is deemed acceptable, it will be sent to the model for processing; otherwise, the user may be informed that the question is inappropriate or the prompt is rejected.
- Sometimes people find ways to bypass the filter. The influence of the prompt on the outcome of LLM can be attributed to several factors. It may be related to probabilistic nature of the model, where prompt provides context and influences probabilities of different responses. Over time, one may discover patterns in the filtering process, but it could also be intrinsic to the model's design.
OpenAI's approach of continually improving models by adding additional layers or components rather than retraining entire model from scratch makes it release new versions so quickly!
| VON NEUMANN ARCHITECTURE | HARVARD ARCHITECTURE |
| Ancient computer architecture based on stored program computer concept. | Modern computer architecture based on Harvard Mark I relay based model. |
| Same physical memory address is used for instructions and data. | Separate physical memory address is used for instructions and data. |
| Common bus for data and instruction transfer. | Separate buses are used for transferring data and instruction. |
| Two clock cycles are required to execute single instruction. | An instruction is executed in a single cycle. |
| It is cheaper in cost. | It is costlier than Von Neumann Architecture. |
| CPU can not access instructions and read/write at the same time. | CPU can access instructions and read/write at the same time. |
| Used in personal computers and small computers. | Used in micro controllers and signal processing. |
- In modern computer systems, executable memory is no longer a common feature. The separation of data and instructions has become standard practice. This approach mitigates the risk of executing malicious code injected into data segments. In LLMs, there is a need for a similar type of distinction between data and instructions. By separating the input data (prompts) from the model's internal instructions (processing), LLMs can enhance security and prevent unintended execution of potentially harmful commands. This separation ensures that the model focuses solely on generating responses based on the input it receives, without the risk of executing arbitrary code.